hadoop集群手动安装
hadoop3.0.0集群手动安装
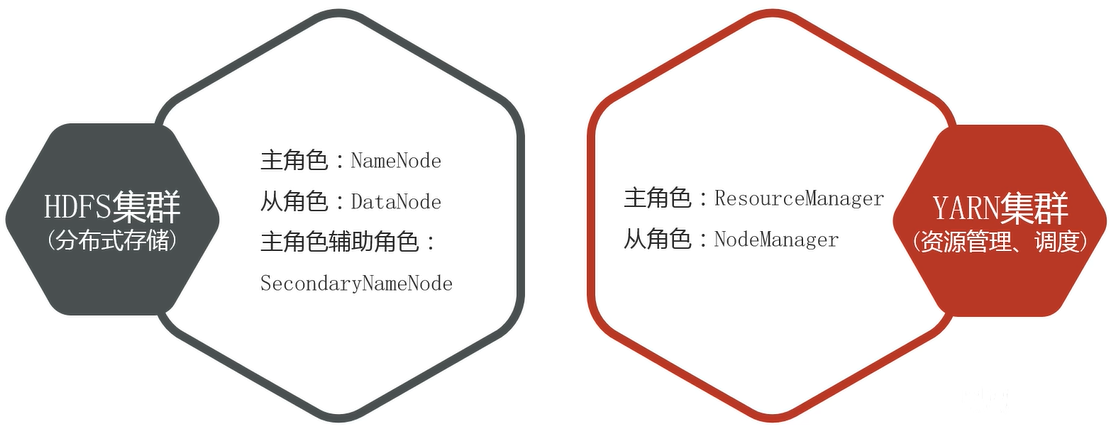
hadoop集群主要涉及到hdfs集群用于分布式存储,主要主角色NameNode,从角色DataNode,主角色负责角色SecondaryNameNode
Yarn集群用于资源管理以及调度,主角色为ResourceManager,从角色为NodeManager
hadoop下载地址https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/
NameNode (NN) :存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(DN):在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode(2NN):每隔一段时间对NameNode元数据备份。
ResourceManager(RN,资源管理器):负责整个系统的资源管理和分配。
NodeManager(NM,节点管理器):在系统中的每个节点上运行,负责监控单个节点资源(CPU、内存等)的使用情况,并向RN报告。
ApplicationMaster(AM,应用程序主控):为每个应用程序单独存在,负责协调应用内的任务,如任务的调度和监控。
理解下,RM是整个集群资源(内存、CPU等)的老大,NM是单个节点服务器资源的老大,AM是单个任务运行的老大
Container: 容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
-
安装jdk8
-
添加hadoop用户
useradd hadoop passwd hadoop vim /etc/sudoers hadoop ALL=(ALL) NOPASSWD: ALL -
配置免密登录
编辑/etc/hosts添加主机映射 192.168.4.26 hadoop01 192.168.4.27 hadoop02 192.168.4.26 hadoop03 su - hadoop ssh-keygen -t rsa ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03 # 每台机器执行 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
配置环境变量
vim /etc/profile.d/hadoop.sh export HADOOP_HOME=/home/bigdata/hadoop-3.0.0/ export JAVA_HOME=/usr/local/jdk1.8.0_144/ export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin:$JAVA_HOME/bin -
配置core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property>
<!--指定 hadoop 集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/bigdata/hadoop-3.0.0/tmp</value>
</property>
<!--hdfs删掉的数据可以从垃圾桶回收,单位分钟-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<property>
<!--namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/bigdata/hadoop-3.0.0/namenode/data</value>
</property>
<property>
<!--datanode 节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/bigdata/hadoop-3.0.0/datanode/data</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- snn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
</configuration>
- 配置yarn-site.xml
<configuration>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 设置 yarn 历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚集日志保留的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- 配置mapred-site.xml
<configuration>
<!-- 设置 MR 程序默认运行模式:yarn 集群模式,local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR 程序历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
- 编辑workers
hadoop01 hadoop02 hadoop03 - 分发hadoop到其他节点
- master节点执行
hdfs namenode -format
12 . 启动hadoop集群
start-dfs.sh
start-yarn.sh
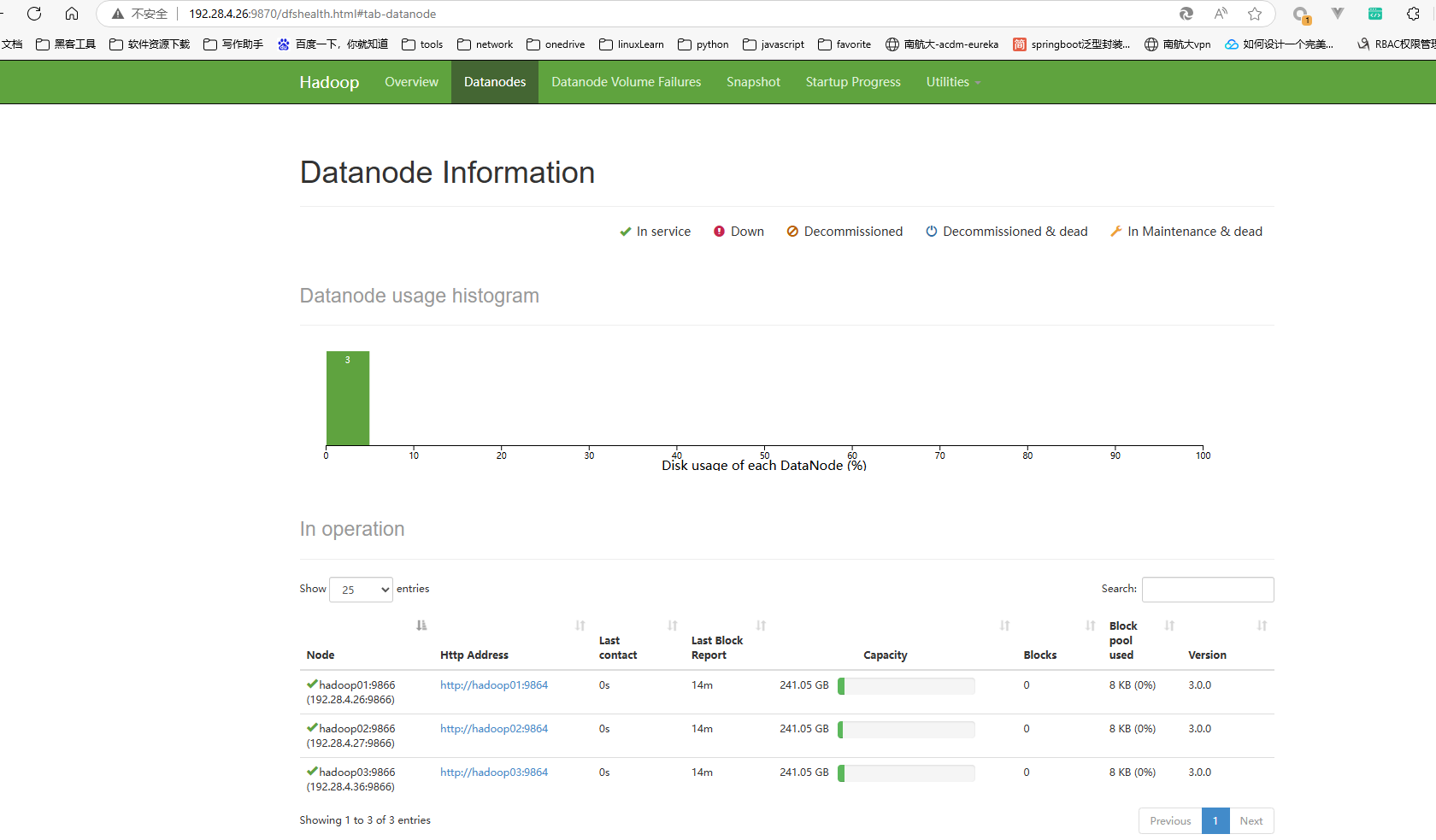
- 访问http://192.28.4.26:9870查看hdfs效果
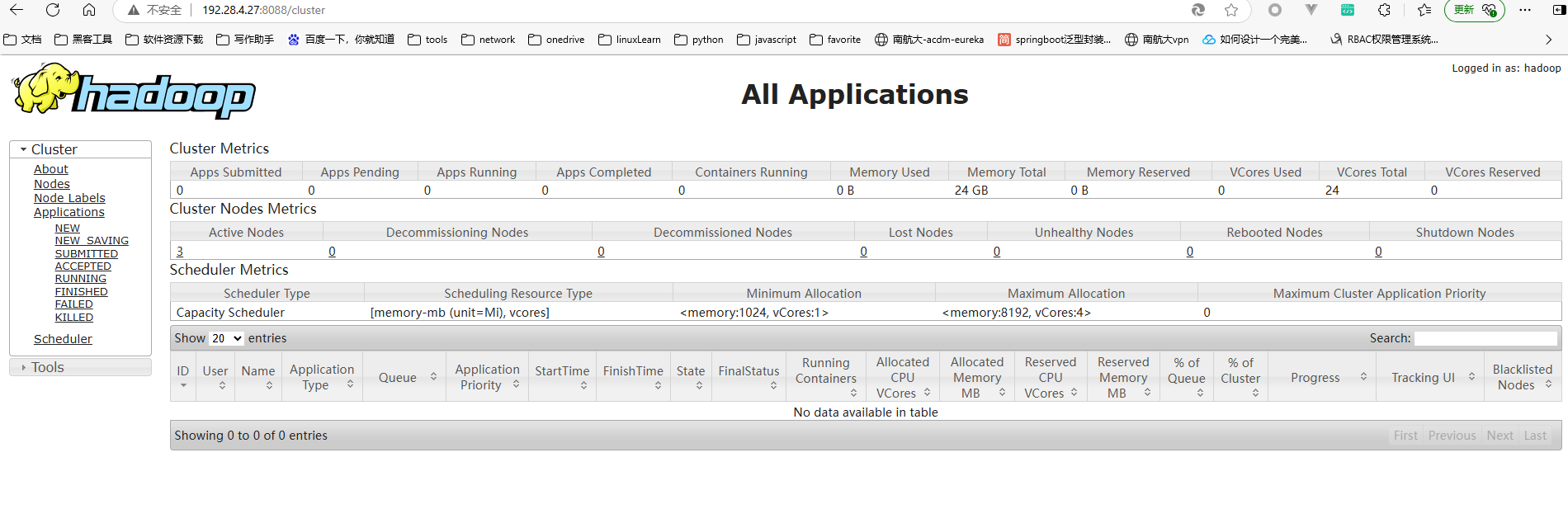
- 访问http://192.28.4.27:8080,查看yarn状态
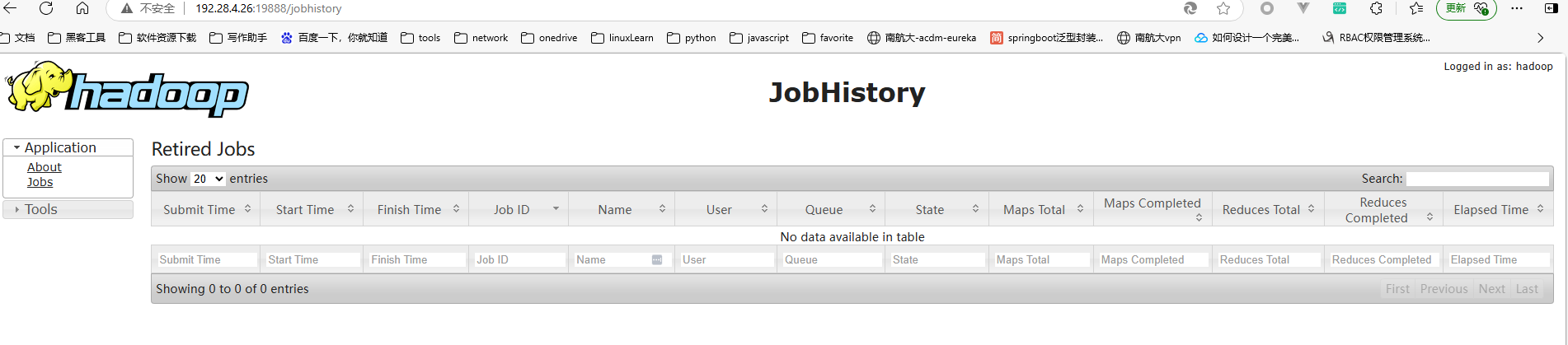
- 在hadoop01执行mapred --daemon start historyserver,访问http://192.28.4.26:19888/jobhistory
hadoop集群手动安装
http://124.220.26.250/archives/hadoop-manual-install